| Des voix chez moi ! Esprits ou paréidolie ? |
|
| Écrit par Fabrice Neyret |
| Mercredi, 26 Octobre 2011 22:06 |
|
Cet article est paru dans notre newsletter n°69 en juillet 2011.
La TCI (TransCommunication Instrumentale, ou encore EVP, pour Electronic Voice Communication) consiste à détecter des messages vocaux, supposés venir de l'au-delà, dans des enregistrements électroniques de sons divers, soit mêlés à un message principal (émission radio, musique, chant d'oiseaux, vent, etc.), soit « capturés » par le truchement d'un son support aléatoire (déchirements, grincements, parasites ou bruits ambiants), voire sans son principal [1]. Il y a quelques semaines, Françoise nous a contacté pour nous soumettre un tel enregistrement, réalisé dans son appartement laissé vide pendant une heure, toute source sonore éteinte. Elle y a isolé l'équivalent d'une minute de sons qu'elle soupçonnait d'être de nature vocale, au milieu de vastes plages de vides ou de bruits du voisinage, dont quelques grincements de chaises. Patiemment, en réécoutant, amplifiant, passant au ralenti [2], elle a noté les mots qu'elle reconnaissait, parfois clairs parfois résistants, puis comblé les vides pour obtenir un ensemble de courtes phrases. Un travail passionné représentant plusieurs dizaines d'heures d'efforts. Je vous conseille d'écouter une première fois un extrait de ce fichier audio immédiatement, avant de lire la transcription qui va suivre (fichier mp3 - 262 ko). En écoutant l'audio, comme d'autres membres de l'OZ, je suis resté dubitatif, comme vous à l'instant : que faut-il entendre ? La minute semble remplie de bruits de meubles que l'on tire et de parasites, sur quoi faudrait-il focaliser son attention ? Puis, quelques jours plus tard, Françoise nous demande des nouvelles, et nous soumet la transcription du décodage de son enregistrement (fichier audio d'une minute, fichier mp3 - 1,1 Mo) : « Explore avec le numérisme » Et là, en réécoutant le fichier avec les paroles sous les yeux, quelle ne fut pas notre surprise : les grincements de meuble prennent une forme de voix, un peu étouffée, mais qui semble prononcer relativement clairement le texte de Françoise ! C'est spectaculaire : réécoutez l'extrait ci-dessus en vous préparant à ce qu'il prononce « vous avez envie de rire... de moi ? ». Personnellement, je n'arrive plus à entendre autre chose, et j'arrive même difficilement à ré-entendre un grincement sur certains « mots ».
Mais l'oreille d'un zététicien averti est méfiante, car elle a déjà entendu des situations d'illusions sonores, aussi appelées paréidolies auditives, les plus classiques étant les chansons en langue étrangère où l'on semble reconnaître de courtes phrases en français. La plus connue ou la plus ancienne est probablement dans la chanson Still loving you de Scorpion, où l'on entend « ce soir, j'ai les pieds qui puent » dans « so strong That I can't get through ». Vérifiez vous-même en regardant le clip. [3] On peut donc entendre deux textes différents sur un même son. Objectivement, à quel point ces deux textes se ressemblent-ils vraiment ? Ils ont bien sûr un timbre et une prosodie (musique de phrase) humaine. Ils ont le même nombre de pieds, et peuvent donc se plier au même rythme « t-t--ttt-t-t ». Ces pieds s'appuient sur des consonnes, parfois les mêmes (les deux S du début), mais le plus souvent pas ! Il est à noter cependant qu'il existe plusieurs familles de consonnes proches, et que certaines correspondances tombent au moins dans la même famille (comme G et Q puis Th et P, à la fin). Quant aux voyelles, les correspondances sont au mieux vaguement ressemblantes : o-e on-oi a-ai aï-é an-ié é-i ou-u. On remarque quelques lettres « avalées », sans correspondance, mais l'oral tolère qu'on avale quelques sons. Et pourtant... vous pouvez entendre à la perfection l'une ou l'autre version !
(C et V désignent des consonnes ou voyelles non-identiques) Pourquoi ? parce qu'en fait, notre cerveau ne se fatigue pas à analyser 100% d'un contenu vocal. Il se trouve que c'est une tâche objectivement très difficile (comme en ont souffert les chercheurs et ingénieurs travaillant sur la reconnaissance vocale par ordinateur), et pourtant il nous faut savoir reconnaître un message même lancé de loin et masqué par les bruits de la nature ou de la ville, même avec un fort accent, même au téléphone, même dans le brouhaha d'une soirée mêlant les conversations ! Ce qui nous sauve, c'est que le langage vocal est très contraint: il y a un rythme et une prosodie, un registre limité de différent sons vocaux significatifs (souvent très tolérants, le français acceptant par exemple de déformer une voyelle à l'intérieur du groupe eao ou iéè), et pour lesquelles seuls quelques enchaînements de syllabes sont autorisés. Toutes ces « règles » qui permettent la robustesse de nos messages à la transmission forcent à des décodages-types des sons, car même si on a mal entendu il y a peu de possibilités. Et bien sûr, le contexte et la connaissance du vocabulaire aident à trouver les mots approchants existants et raisonnables en cas de lacune ou de transcription douteuse, comme fait le correcteur orthographique associé à un logiciel de scannage de texte. On voit donc que des correspondances assez superficielles suffisent à bien reconnaître comme plausible une transcription. Car le pendant de la robustesse est que cela peut conduire à reconnaître des messages même quand il n'y en a pas. Ainsi, un logiciel de reconnaissance vocale peut décrypter un mot dans un bruit de photocopieuse, et un logiciel de reconnaissance de l'écriture peut déchiffrer des lettres dans des bavures.
Mais avec les chansons, il s'agit de voix humaines, même si on joue entre deux langues différentes. Quid pour les sons qui ne sont pas humains ? Et d'abord, comment reconnaître la nature « humaine » d'un son ? De fait, la voix repose en partie sur les règles vocales citées plus haut, mais aussi sur la constitution même des timbres qui définissent des voyelles et des consonnes, qui les caractérisent et les distinguent des instruments de musique, des souffles, des craquements ou des chocs. Un son voyelle, c'est un timbre où se détache essentiellement un accord de trois notes (ou « formants »), dont les rapports d'écarts font la voyelle signifiante que vous identifiez. On peut définir l'accord de « a » idéal, mais en pratique tout accord entendu dans un son est peu ou prou associé à la voyelle présentant des écarts proches. D'autant que comme on l'a dit, la confusion entre voyelles proches n'est elle-même pas très grave pour la reconnaissance d'un mot. Conséquences : divers sons comprenant un accord dominant de trois notes peuvent s'entendre comme une voyelle, et divers sons de souffle ou de percussion peuvent s'entendre comme une consonne, possiblement indéterminée comme quand le son est étouffé, mais rangée dans une famille.
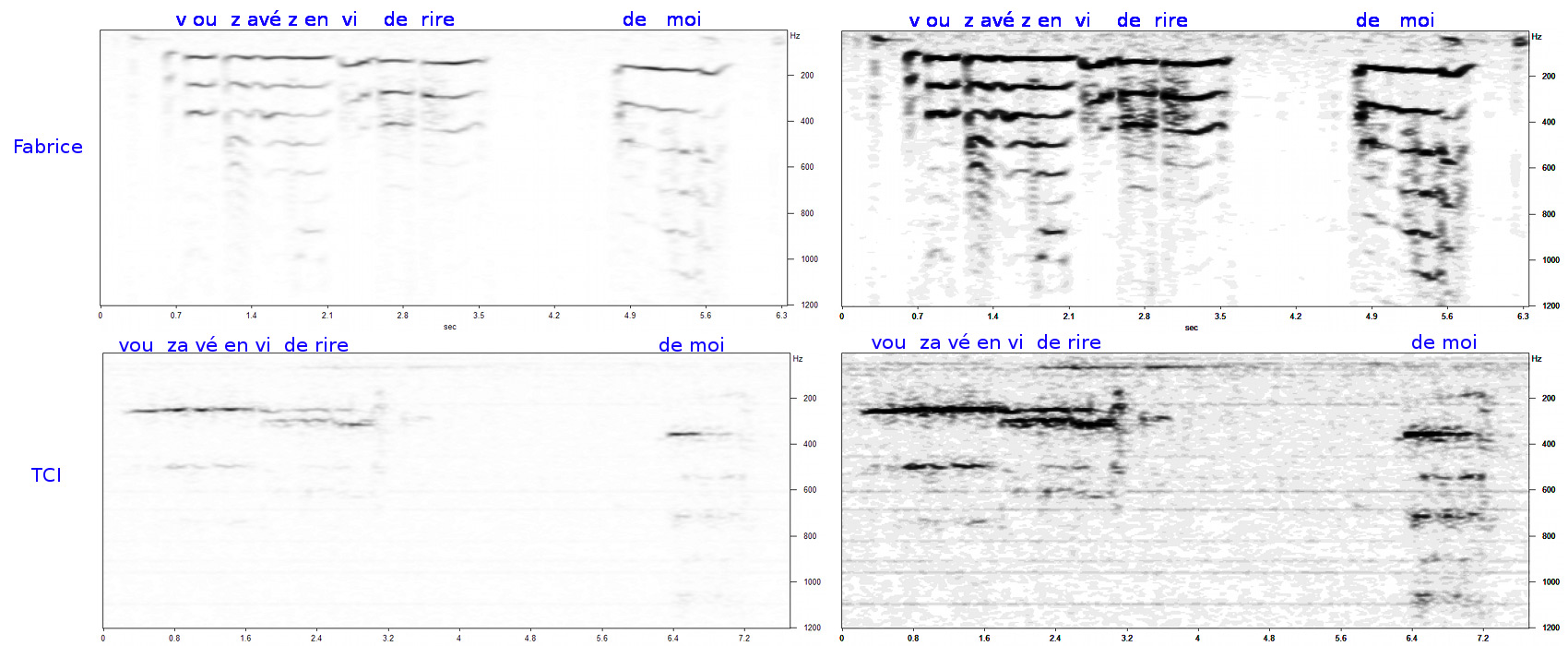
Quels sons fortuits peuvent produire des notes ? Une note est une oscillation mécanique stable, par exemple parce qu'elle correspond à une fréquence propre : la matière ou l'air d'un tube, une fente, une corde ou une surface est excitée par des chocs, des frottements, un souffle, et s'agite selon une onde mécanique compatible avec ses dimensions, vibration qui met ensuite en mouvement l'air extérieur, engendrant l'onde sonore qui se propage jusqu'à nos oreilles. Quand on tire un meuble, des surfaces sont excitées par frottement (côté meuble et côté sol), et selon les points de contact l'une ou l'autre de ses dimensions va sculpter une vibration mécanique produisant une certaine note. En pratique, il y a des chances que plusieurs se combinent. Un frottement sur bois produit donc potentiellement des accords, éventuellement compatibles avec des voyelles. Tirer un meuble s'accompagne vraisemblablement de quelques chocs : passage de lattes ou de carreaux au sol, décoincements brusques, instabilités de parties articulées (tiroirs). Voici de quoi sécréter des consonnes. Si un long geste de déplacement de meuble est tenu sur un parcours combinant des modulations de grincements et des répétions de chocs, on a donc tout ce qu'il faut pour produire du son « pseudo-vocal » avec son rythme, sa prosodie, ses « voyelles » et « consonnes ». Toutefois, la proximité est suffisamment ténue pour que la reconnaissance initiale demande un effort. À ce stade, comme beaucoup de sons naturels longs et modulés (glouglou de ruisseau, chuintement du vent), on pourra avoir une impression de voix sans vraiment reconnaître de mots, comme un chuchotement discret ou une clameur lointaine. Mais si à force de tâtonnements, on retravaille la vitesse ou la tonalité des différents sons pour améliorer sa « perception », alors on fabrique de plus en plus de raisonnables voyelles et consonnes. Les règles d'assemblage linguistique évoquées plus haut nous proposent quelques combinaisons de syllabes possibles, que les limites lexicales contraignent en mots possibles dans notre langue. On se retrouve alors dans le cas de la paréidolie musicale. La proximité distendue entre son entendu et phrases ainsi élaborées suffit pour que l'on identifie perceptivement ce qu'on entend à ce qu'on est persuadé d'entendre : on écoute moins avec son oreille qu'avec son cerveau. Comme on l'a signalé plus haut, il est bien plus facile de reconnaître une phrase paréidolique que de la décrypter la première fois. En fait, notre perception s'appuie sur un renfort prédictif : l'audition est préamplifiée (et ce, même physiologiquement) sur les sons possibles attendus, que ce soit à cause des contraintes linguistiques ou de notre connaissance du texte. D'où la difficulté à entendre autre chose une fois que l'on tient une interprétation. Pour tester l'hypothèse « le fichier de Françoise n'est pas une voix mais plutôt un grincement », on peut observer le spectrogramme de l'extrait audio (« TCI », en bas), et le comparer à celui d'une personne (« Fabrice », en haut) lisant l'interprétation de texte avec un timbre proche. Le spectrogramme ci-dessous donne verticalement l'équivalent des niveaux de graves et d'aigus de votre Hi-fi, avec des graduations bien plus fines, l'axe horizontal représentant le temps. Les images de droite montrent tous les détails du contenu sonore et celles de gauche sont des versions « épurées » ne retenant que les parties suffisamment intenses.
(Cliquez sur l'image pour la voir en grand).
Comme vous l'aurez constaté avec l'extrait sonore, les quelques propriétés de ce son sont insuffisantes pour identifier des mots en première audition, mais suffisantes pour caler et reconnaître un texte satisfaisant aux correspondances évoquées (rythme, pieds, famille de « voyelle », famille de « consonnes » quand articulé). Trouver ce texte est laborieux tandis que le reconnaître est aisé, ce qui n'arrive en principe pas avec une voix humaine.
Pour conclure, l'hypothèse « paréidolie auditive » est très plausible, et conforme aux phénomènes déjà connus de la science (des matériaux et de la parole), tandis que l'hypothèse « esprits parlants », extraordinaire au point qu'il faudrait considérablement modifier les connaissances scientifiques en cas de confirmation, ne semble avoir aucun argument la rendant plus explicative que l'autre. Le rasoir d'Ockham (ou principe de parcimonie) incline donc à préférer la première hypothèse. Cependant, il ne s'agit pas encore d'une preuve. Le clou de la démonstration consisterait à essayer de « trouver » plusieurs textes différents bien adaptés au même son, de sorte que l'auditeur estime chaque interprétation satisfaisante quand il écoute le son avec le texte sous les yeux (ou, dit autrement, de tester si différents décodeurs de TCI travaillant indépendamment peuvent « entendre » des phrases différentes dans un même texte). Dans l'hypothèse « esprits parlants », c'est improbable puisqu'un message précis est objectivement transmis. Dans l'hypothèse « paréidolie », on doit pouvoir « entendre » plusieurs messages possibles. Il y a des chances que certaines syllabes soient consonantes entre les différents textes au vu des contraintes acoustiques et linguistiques, mais cela devrait laisser tout de même plusieurs assemblages lexicaux possibles. Le problème est qu'une fois qu'on a entendu une interprétation, il est très difficile d'entendre autre chose. Pour faire cette expérience, il faut donc repartir d'un son « vierge de toute interprétation », puis faire plancher plusieurs personnes motivées sans contact entre elles pendant leur travail. Qui veut essayer ? Françoise nous a fourni d'autres sons. Faites nous parvenir les messages que vous y percevrez pour l'un ou l'autre extrait ! (casque et logiciel de traitement du son recommandés) :
La suite de l'histoire est ici : https://evasion.imag.fr/~Fabrice.Neyret/debats/zetetique/BACKUP/335-poz-nd71.html Fabrice Neyret [1] : plus d'infos sur la description, l'historique et les interprétations du phénomène sur Wikipédia, plus complet en version anglaise. |